GPT-4V:166页说明书讲解又全又详细
2023-10-08 MedSci原创 MedSci原创 发表于上海
多模态王炸大模型GPT-4V,166页“说明书”重磅发布!不仅详细测评了GPT-4V在十大任务上的表现,从基础的图像识别、到复杂的逻辑推理都有展示;还传授了一整套多模态大模型提
多模态王炸大模型GPT-4V,166页“说明书”重磅发布!不仅详细测评了GPT-4V在十大任务上的表现,从基础的图像识别、到复杂的逻辑推理都有展示;还传授了一整套多模态大模型提示词使用技巧。
他们对GPT-4V完成各类任务的能力进行评估,还给出了使用GPT-4V的新提示词技巧。总之,GPT-4V性能炸裂,不过据说GPT-5在半年前已训练完毕,现在正在安全调优中,不知道GPT-5又会给出什么样的惊人的本领。
1、GPT-4V的用法:
5种使用方式:输入图像(images)、子图像(sub-images)、文本(texts)、场景文本(scene texts)和视觉指针(visual pointers)。
3种支持的能力:指令遵循(instruction following)、思维链(chain-of-thoughts)、上下文少样本学习(in-context few-shot learning)。
例如这是基于思维链变更提问方式后,GPT-4V展现出的指令遵循能力:
2、GPT-4V在10大任务中的表现:
开放世界视觉理解(open-world visual understanding)、视觉描述(visual description)、多模态知识(multimodal knowledge)、常识(commonsense)、场景文本理解(scene text understandin)、文档推理(document reasoning)、写代码(coding)、时间推理(temporal reasonin)、抽象推理(abstract reasoning)、情感理解(emotion understanding)
其中就包括这种,需要一些智商才能做出来的“图像推理题”:
3、类GPT-4V多模态大模型的提示词技巧:
提出了一种新的多模态提示词技巧“视觉参考提示”(visual referring prompting),可以通过直接编辑输入图像来指示感兴趣的任务,并结合其他提示词技巧使用。
4、多模态大模型的研究&落地潜力:
预测了多模态学习研究人员应该关注的2类领域,包括落地(潜在应用场景)和研究方向。例如:
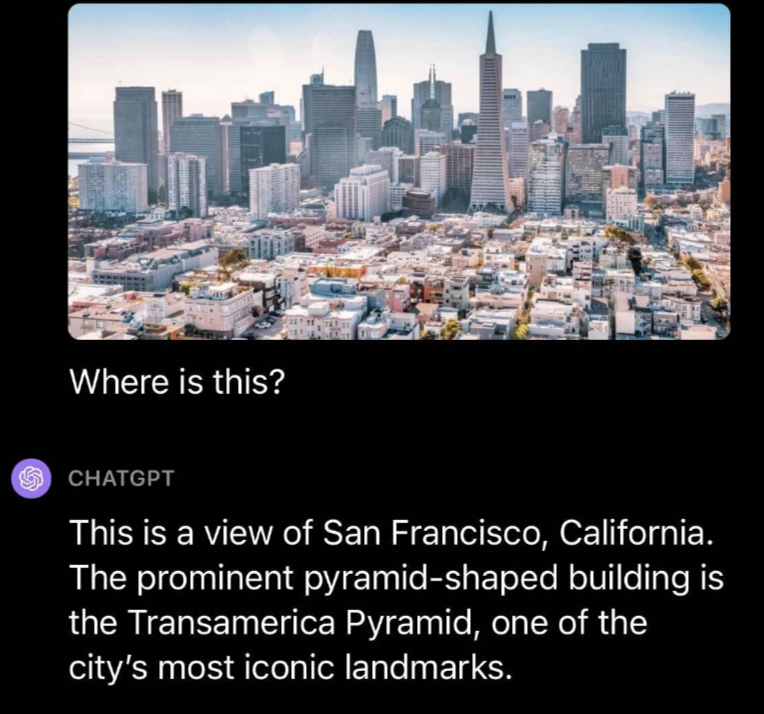
例如这是研究人员发现的GPT-4V可用场景之一——地理识别:
我们通过询问有关地点的问题来探索 GPT-4V 的问答功能。 我们上传了一张旧金山的照片,并附有文字提示“这是哪里?” GPT-4V 成功识别了旧金山的位置,并指出我们上传的图片中的泛美金字塔是该市的一个著名地标。
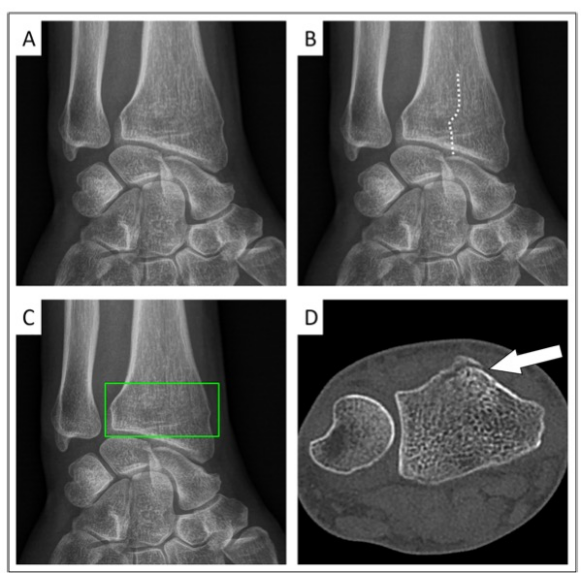
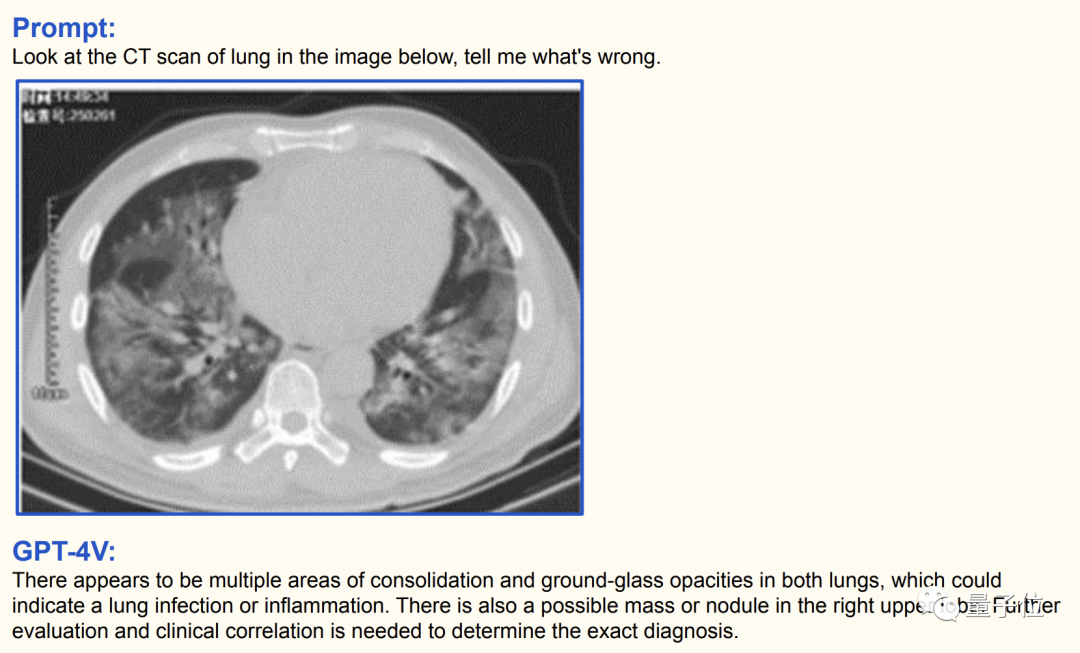
对于专业的医学影像,针对下面这张肺部CT,GPT-4V给出了这样的结论:
双肺多个区域存在实变和磨玻璃混浊,肺部可能存在感染或炎症。右肺上叶也可能有肿块或结节。
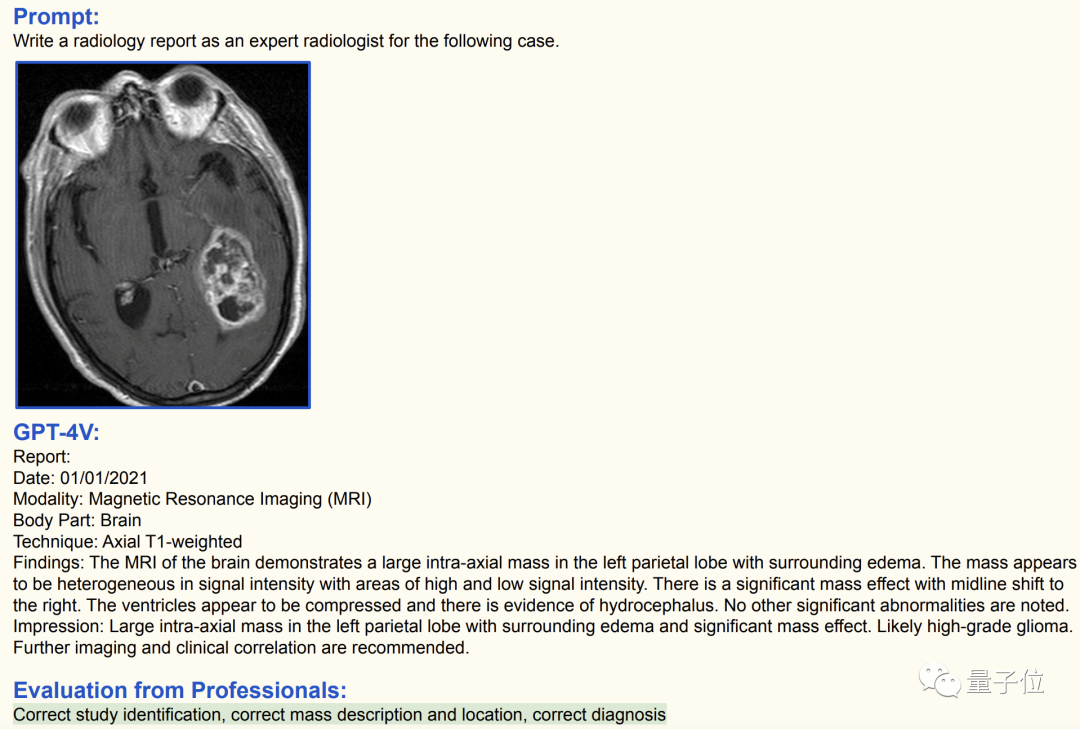
甚至不告诉GPT-4V影像的种类和位置,它自己也能判断。
这张图中,GPT-4V成功识别出了这是一张脑部的核磁共振(MRI)影像。
同时,GPT-4V还发现存在大量积液,认为很可能是高级别脑胶质瘤。
经过专业人士判断,GPT-4V给出的结论完全正确。
然而,由于 GPT-4 与 Vision 和其他人工智能模型带来的潜在隐私、公平和网络安全问题,所有用户都应保持谨慎。
除了图像输入功能之外,OpenAI 还重新启用了 Browse with Bing 功能,以便通过 ChatGPT 进行网页浏览。
 GPT-4V:166页说明书讲解又全又详细
GPT-4V:166页说明书讲解又全又详细
本网站所有内容来源注明为“梅斯医学”或“MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明来源为“梅斯医学”。其它来源的文章系转载文章,或“梅斯号”自媒体发布的文章,仅系出于传递更多信息之目的,本站仅负责审核内容合规,其内容不代表本站立场,本站不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言